Recently I added an experimental implementation of Paul Doust’s No arbitrage SABR model to QuantLib. As the name suggests this is an arbitrage free approximation to the famous stochastic 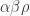

for a forward rate 





I am not going to talk about low interest rates and possible remedies for your models here, it is weekend after all, so let’s relax and don’t worry about the outside world too much – I think it was just yesterday that the Euro Sabr Volatility Cube in QuantLib ceased to work, telling me that the 1m into 1y forward swap rate against Euribor 3m is negative, so no further activity seems meaningful any more. Thursday was also quite interesting thanks to our swiss neighbours. I mean how are you supposed to stay focussed when everybody around you freaks out ? Really annoying.
Once the no arbitrage model core itself was implemented I needed to integrate it into the existing infrastructure. For the classic SABR implementation there are a lot of useful classes, like an interpolation class and associated factory, a smile section, a swaption cube (the one from above). The quick and dirty solution is too obvious: Copy’n’paste the existing SABR code, rename the classes and replace the SABR formula by the new Doust version. I think, ultimately, there are only three very simple criteria for good code
- No redundant code – don’t do the same thing at two places in your program
- Easy to maintain and extend – bug fixing and adding new functionality is easy
- Understandable – the average colleague of yours is able to read and understand the code
The better approach for integrating the new SABR version seems therefore to take the existing code, extract everything specific to the classic implementation and use what is left to build both SABR versions on top of it. I called the common basis XABR, so for example there is now a class
template <class I1, class I2, typename Model>
class XABRInterpolationImpl :
public Interpolation::templateImpl<I1, I2>,
public XABRCoeffHolder<Model> {
/* ... */
with a generic Model class giving the specification of Hagan’s 2002 SABR approximation, Doust’s 2012 no arbitrage SABR approximation, and possibly other models. Turns out that for example the SVI model also fits into the framework without any difficulties. So the label XABR is already not general enough to cover all use cases. Never mind, the main thing is that the code is generic. The Model class looks like this
struct SABRSpecs {
Size dimension() { return 4; }
void defaultValues(std::vector<Real> ¶ms, std::vector<bool> &,
const Real &forward, const Real expiryTIme) {
/* ... */
}
void guess(Array &values, const std::vector<bool> ¶mIsFixed,
const Real &forward, const Real expiryTime,
const std::vector<Real> &r) {
/* ... */
}
Real eps1() { return .0000001; }
Real eps2() { return .9999; }
Real dilationFactor() { return 0.001; }
Array inverse(const Array &y, const std::vector<bool>&,
const std::vector<Real>&, const Real) {
/* ... */
}
Array direct(const Array &x, const std::vector<bool>&,
const std::vector<Real>&, const Real) {
/* ... */
}
typedef SABRWrapper type;
boost::shared_ptr<type> instance(const Time t, const Real &forward,
const std::vector<Real> ¶ms) {
return boost::make_shared<type>(t, forward, params);
}
};
telling you the number of parameters of the model, default values to be used as starting values for calibration (if you do not specify any), a guessing algorithm giving meaningful alternative starting values if the first calibration fails or runs into a local minimum, some internal constants (not part of the Model concept directly) and inverse and direct transformation methods that map the full real hypercube to the admissible parameter space to facilitate unconstrained optimization of the model. Last not least, the instance method creates an object of the model that can be used to ask for implied volatilities.
This kind of generalization is also done for volatility cubes. Now there is a
template<class Model>
class SwaptionVolCube1x : public SwaptionVolatilityCube {
/* ... */
again taking a generic spec for the desired underlying model. The original Hagan cube and the new Doust cube are then retrieved as
struct SwaptionVolCubeSabrModel {
typedef SABRInterpolation Interpolation;
typedef SabrSmileSection SmileSection;
};
typedef SwaptionVolCube1x<SwaptionVolCubeSabrModel>
SwaptionVolCube1;
struct SwaptionVolCubeNoArbSabrModel {
typedef NoArbSabrInterpolation Interpolation;
typedef NoArbSabrSmileSection SmileSection;
};
typedef SwaptionVolCube1x<SwaptionVolCubeNoArbSabrModel>
SwaptionVolCube1a;
Pretty pretty pretty good. But what does that have to do with “Tag Dispatching” ? And is ZABR just a typo in the headline of this post ? No. I don’t know what the Z stands for (probably for nothing), but it labels a model invented by ingenious Jesper Andreasen aka Qwant Daddy at Danske Bank. I once had the luck to attend a presentation he gave. Very impressive. Anyway, the model is this

so introducing a CEV dynamics for the volatility. With that you can control the wings of your smile in a very flexible way, which is nice if you are into CMS pricing for example. Although I have to mention that too many degrees of freedom are not always helpful. I make do with the classic SABR model for the Euro CMS market currently and ZABR is currently not more (and not less) than an interesting bird of paradise.
I implemented the ZABR paper (it is called expansions for the masses for some reason similarly clear as the Z in ZABR) back in 2012 in our summer holidays on Sardinia. Brutally hot three weeks, forest fires nearby our house still burning just the day before we arrived. I called our landlord, he telling me everything is safe, guess then it is ok to go there with your wife and four little kids, ain’t it. Well after all it was nice on Sardinia and the worst thing that happened was that this little rocker of the L key on my beloved laptop broke. Heroically I finished the implementation nevertheless.
The special thing about the implementation is that the paper suggests more than one solution of the model. For a start there are short maturity expansions in lognormal or normal volatility, comparable in computational complexity to the classic Hagan expansions. Then there is a Dupire style local volatility approach producing an arbitrage free smile yet at the same time being fast to evaluate. And, not in the paper, I added a brute force precise full finite difference solution, which is slow but useful to benchmark the approximations.
Originally I used an enum parameter in the constructor of the model to specify the way of model evaluation. But that doesn’t fit in the above XABR framework. Extend the XABR concept to take an additional parameter that is not needed otherwise ? Not very nice. A light variant of Tag Dispatching can help ! The idea is to have a template parameter that denotes the evaluation and then write the spec for the model like this
template <typename Evaluation> struct ZabrSpecs {
Size dimension() { return 5; }
Real eps() { return 0.000001; }
void defaultValues(std::vector<Real> ¶ms,
std::vector<bool> ¶mIsFixed, const Real &forward,
const Real expiryTime) {
/* ... */
}
/* ... */
typedef ZabrSmileSection<Evaluation> type;
boost::shared_ptr<type> instance(const Time t, const Real &forward,
const std::vector<Real> ¶ms) {
return boost::make_shared<type>(t, forward, params);
}
/* ... */
The good thing about this is that the spec itself is templated by the evaluation, so that the evaluation does not need to become a parameter in the spec methods (e.g. the instance method), they can just stay the same as before. In this way this approach is not intrusive at all, fully respecting the existing code structure.
To mimic the functionality of an enum I chose the Evaluation parameter to be a tag meaning that it is just a label with no other deeper meaning in its simple and superficial yet useful (so I assume ultimately happy) existence. That is I declare empty classes
struct ZabrShortMaturityLognormal {};
struct ZabrShortMaturityNormal {};
struct ZabrLocalVolatility {};
struct ZabrFullFd {};
which can be plugged into the interpolation class quite naturally like this
ZabrInterpolation<ZabrLocalVolatility> myInterpolation(/*...*/); /*...*/
But how is the implementation itself done ? For example let’s look at the volatility implementation of the ZABR smile section
Volatility volatilityImpl(Rate strike) const {
return volatilityImpl(strike, Evaluation());
}
It invokes a method with the same name, but a second parameter which is just an instance of our tag class. This parameter is not carrying any information, it is an instance of an empty class declaration. It is just used to make the compiler choose one of the overloaded versions of volatilityImpl appropriate for the kind of evaluation specified. Thuss we have several private overloaded methods
Volatility volatilityImpl(Rate strike, ZabrShortMaturityLognormal) const;
Volatility volatilityImpl(Rate strike, ZabrShortMaturityNormal) const;
Volatility volatilityImpl(Rate strike, ZabrLocalVolatility) const;
Volatility volatilityImpl(Rate strike, ZabrFullFd) const;
one for each evaluation tag. This produces more efficient code than switch statements dispatching the evaluation mode at runtime. Also the code is more readable because each evaluation is implemented in its own overloaded method – still retaining the possibility of shared code between the different kinds of evaluation of course. No redundant code. And new evaluation modes can be added in a most transparent way.
If you are interested in the full code for the ZABR implementation you can have a look at https://github.com/lballabio/quantlib/pull/168/files. If you are interested in the model itself, there are some slides about that in my presentation at http://quantlib.org/qlws14.shtml. If you find it hard to read and understand Jesper’s and Brian’s original paper, I can send you a rewritten version I created for the masses (and in particular for myself) with all the intermediate steps not crystal clear except you are a risk quant of the year.
As a final and totally unrelated remark. Even if you are not into Jazz music, here is a gem everyone should give a chance (and soon get addicted to): Wonderful Brad Mehldau’s album Where Do You Start http://en.wikipedia.org/wiki/Where_Do_You_Start. The fragile-pessimistic-yet-easy-funky Got Me Wrong, the probably coolest (sorry Jimi) version of Hey Joe ever heard (though I did not listen to all of the apparently more than 1700 versions out there https://heyjoeversions.wordpress.com/hey-joe-versions/), the simply beautiful Samba e Amor evolving into Brad’s own Jam, the so much sensible and consoling Time Has Told Me. Pure art. Give it a try.

Hi, Am interested in trying out your implementation of Paul Doust Arbitrage free SABR and Brians ZABR. You mention you have an additional document that explains the process. Could you kindly share it, many thanks. Look forward to hearing from you. Raman
My e mail id is raman.delhi@gmail.com
LikeLike
[…] prices and not directly volatilities. Or of course the ZABR model which we already had on this blog here and which has premium outputs at least for some of its […]
LikeLike
Hello, as unfortunately I am not the quant of the year 😥 I would really like to have a look at your version of the article. The original paper is very cumbersome for me.
May I kindly ask you to send it to me at ceikit@hotmail.it ?
Thank you very much!
LikeLike
Hello!
I would really like to have a look at your version of the article as the original one is very cumbersome for me.
May I kindly ask you to send me your version at ceikit@hotmail.it ?
Thank you very much in advance.
Filippo
LikeLike
I made my notes available for download here http://ssrn.com/abstract=2692048
LikeLike
Hello! Is your code exposed via Python wrappers of QuantLib?
LikeLike
No, unfortunately not. It shouldn’t be very hard to extend the SWIG wrappers though.
LikeLike
Thanks, Peter. Do you know of anyone who might be interested in extending the wrappers to include this code? Seems like this is a way to broaden the user-base significantly.
LikeLike
Hi Edith, not really. This is a general problem, all QuantLib dev is done by volunteers, so everyone is adding what they need, but not much more, at least not if there is no known demand. But you might ask on the quantlib user list for help or (probably better) open a ticket on github requesting specific extensions of the wrappers. It’s possible that someone takes the ticket then.
LikeLike